In this blog post, we will aim to understand how using code for server infrastructure provisioning can reduce the man-hours required by hundreds of times, and also improve uptime drastically.
Environments for a Standard Web App
Let us consider we are building a standard web application of a small / medium enterprise. We would have atleast 4 different environments —
- CI / Dev: The builds are automatically deployed to this environment and functional tests run here.
- QA / Testing: Passing builds manually promoted by the QA depending on what needs to be tested.
- Staging: Release candidates deployed here.
- Production: Used by the end users.

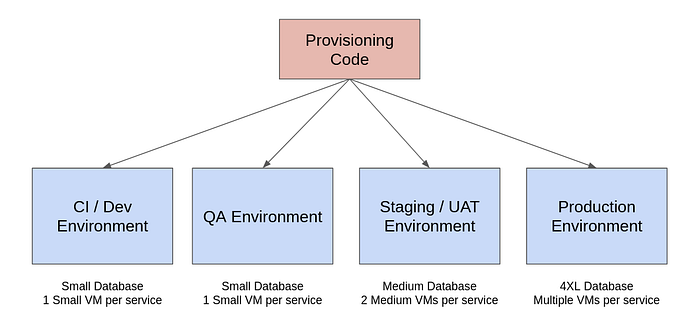
The CI and QA environments would typically have small databases, and small virtual machines hosting each service. The staging would generally have more resources, and the production environment would have larger databases, and multiple VMs / Containers / Functions for every service, depending on the load.
Hosting Environments on the Cloud
If we’re deploying on AWS, here is a snapshot a few of the components typically used by us —

For even a small to medium scale enterprise, the components quickly start running into hundreds. For example, below is snap of some of the components used in a medium scale enterprise for just a single environment. There are over 40 buckets, 75 lambda functions, 13 DB clusters, 9 data streams, 10 EC2 instances, 25 API gateways, and many more components not shown in the picture.

The Infrastructure Team’s Job
Imagine the job of the infrastructure team. For each environment they would have to manually create 13 DB clusters one after the other. Same for the lambda functions, API Gateways, EC2 instances etc. If they make a small mistake in the way they’re creating the EC2 instances, or realise a security flaw, they would have to manually go and change / recreate each of them.
This is just for 1 environment. For 4 different environments, this job is repeated 4 times.
The Problem
The infrastructure team has to setup and maintain 100s of infrastructure components across multiple environments with minor variations.
It has a really difficult, time consuming job, full of repetitive jobs with high potential for mistakes.
Here are some examples of the kind of problems they may face -
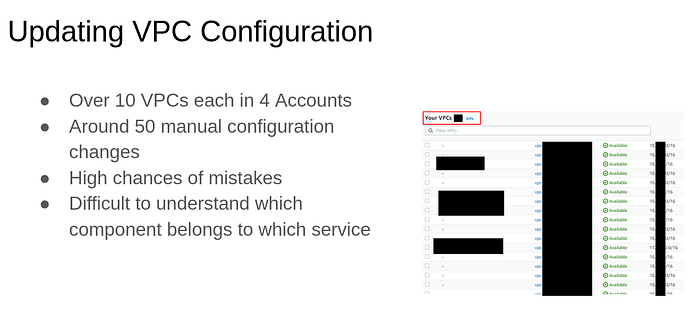
Problem 1: Updating VPC Configuration
Assume that there are over 10 VPCs each in 4 accounts. This means we have to manually change around 50 times. Looking at the AWS Console, it becomes difficult understanding which VPC is connected to which other components, and what service does it relate to. This can lead to high chances of mistakes when done manually.
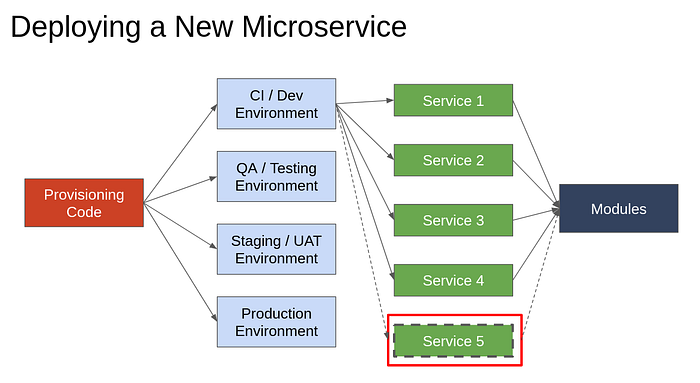
Problem 2: Deploying a New Microservice
One Microservice deployment contains 10–15 different types of resources (VPCs, S3 Buckets, Roles, Keys, DBs etc) . To deploy microservices in 4 accounts, this has to be replicated 4 times, leading to manual creation of over 50 resources. This is again a tedious, repetitive, and time consuming job.

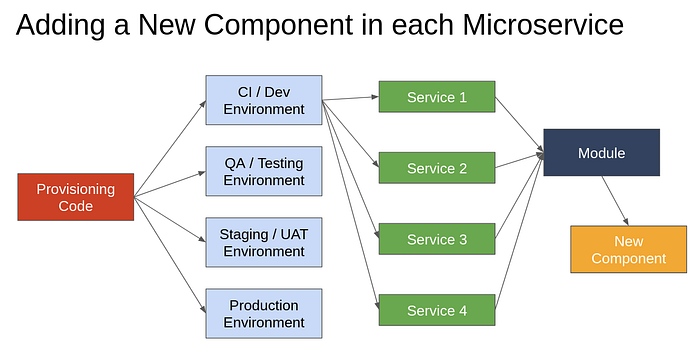
Problem 3: Adding a New Component in Each Microservice Deployment
There might be a component that we realise later that we need as a part of each microservice. For example, we might want to add an API gateway to route requests a certain way.
This would mean updating around 10–15 services each across 4 environments, resulting in manually adding 50 components. For the infrastructure team, this means manually figuring out where to add the new component, how to link it to each service correctly, and test it to confirm it works fine.

Summary of the problem: Making infrastructure changes manually means repeating the same step over and over again, with the additional effort of trying to keep a mapping in the head of which changes are done and which are remaining, and which resource belongs to which component.
The Solution
The solution here is pretty obvious —We need to automate the provisioning of infrastructure. When we have code that creates various components, all we have to do is update the code and run it again, and all the infrastructure gets updated.
If you’ve used a build server like Jenkins or Gitlab CI to do your deployments, you must have seen Single Click Deployment in action and how easy it makes releasing new versions of the app. This is similar, except that we’re now doing Single Click Infra Provisioning and Single Click Infra Updation.
We would have just one provisioning code for all 4 environments. The differences in database sizes and service capacity can be handled by having an account specific configuration that specifies these details.
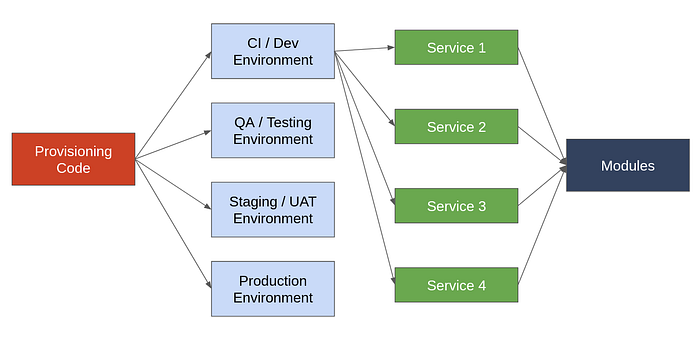
To make it easier to make changes only in once place, we can divide the infrastructure code into modules. For example, the code to create a postgres database could be in one module, code for nosql database creation in another, and the code to create a reverse proxy server in a third. This way, every infrastructure component would have its own module.
Here is how this can solve the problems we described -
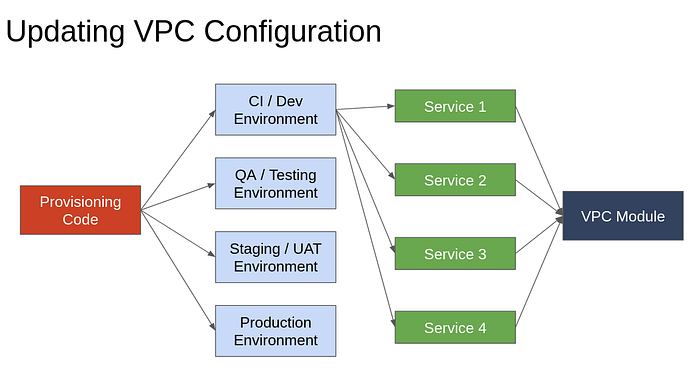
Problem 1: Updating VPC Configuration
If we divide provisioning different components into modules, VPC setup can be its own module. To update the VPC configuration of all VPCs of all services across all environments, all we need is to change this one module. This way the change can be propagated to all VPCs and something that would have taken a whole day earlier can now be done in a matter of minutes.
Problem 2: Deploying a New Microservice
To create infra for a new Microservice, we can have service modules. Each service module would just call the components it requires. To deploy a new microservice, we’d need to just create another service module that internally calls those component submodules that are required.
Problem 3: Adding a New Component in Each Microservice Deployment
The new component that we add will be a part of either an existing module, or we might need to create a new module in itself. If it can be bunched with an existing module, we just need to change one piece of code. If it needs to be a new module, we’ll need to call it from each of the new services. It is still easier than manually going and doing that process.
Infrastructure as Code (IAC)
Overall, server infrastructure management is a repetitive and time consuming process. Like any repetitive and time consuming process, it can be automated.
The practice of using code to setup and manage our server infrastructure is called Infrastructure as Code (IAC).

What Next?
The most popular IAC tool in the market is Terraform. To understand what is Terraform, I would recommend reading this blog post. I also recommend watching the video below to see a hands-on demo of Terraform in practice —
